こんにちは。PALO ALTO INSIGHT辻です。ニューラルネットワークでよく使われるKerasですが、以前はPythonのみサポートされていましたが、Rでも使うことが可能になったので、今日は使い方の1例を紹介させて頂きます。
Rでは「keras」と「kerasR」というパッケージが利用可能ですが、今回は「keras」パッケージを紹介します。これにより、Rでもさらにニューラルネットワークの分析がしやすくなりました。また、損失関数を別途定義する際の注意事項なども紹介します。
データのダウンロード
keras datasetの「ボストンの住宅価格データセット」を使用してニューラルネットワークで線形回帰を行いたいと思います。データ項目名などの詳細に関してはURLを参照ください。インストールされていないパッケージはinstall.package(‘パッケージ名’)などでダウンロードしてください。
# 必要なライブラリーの読み込み
library(ggplot2)
library(tidyr)
library(dplyr)
library(keras)
# データを読み込んでデーターフレームに入れる。
dataset = dataset_boston_housing()
c(c(x_train, y_train), c(x_test, y_test)) %<-% dataset # トレーニングデータを正規化する x_train = scale(x_train, center = TRUE, scale = TRUE) center_train = attr(x_train, “scaled:center”) scale_train = attr(x_train, “scaled:scale”) x_test = scale(x_test, center = center_train, scale = scale_train) kerasパッケージでモデルを作る Rの「keras」パッケージではパイプ「%>%」を使って階層を組み立てます。Rをすでにお使いの方は「dplyr」と使い方が一緒なのでわかりやすいと思います。
# モデルの立ち上げ
model = keras_model_sequential()
# %>% を使ってレイヤーの設定を行う。以下中間層を2つ使った例
base = c(ncol(x_train))
model %>%
layer_dense(units = base, activation = “tanh”, input_shape = base, name = “firstLayer”) %>%
layer_dense(units = ncol(x_train), activation = “tanh”, name = “secondLayer”) %>%
layer_dense(units = 1, activation = “linear”, name = “predictions”)
# Optimizerと損失関数の指定
model %>% compile(optimizer = optimizer_nadam(), loss = ‘mse’)
# トレーニングの実行
historyTrain = model %>% fit(x_train, y_train, epochs = 250, batch_size = 5, verbose = 0)
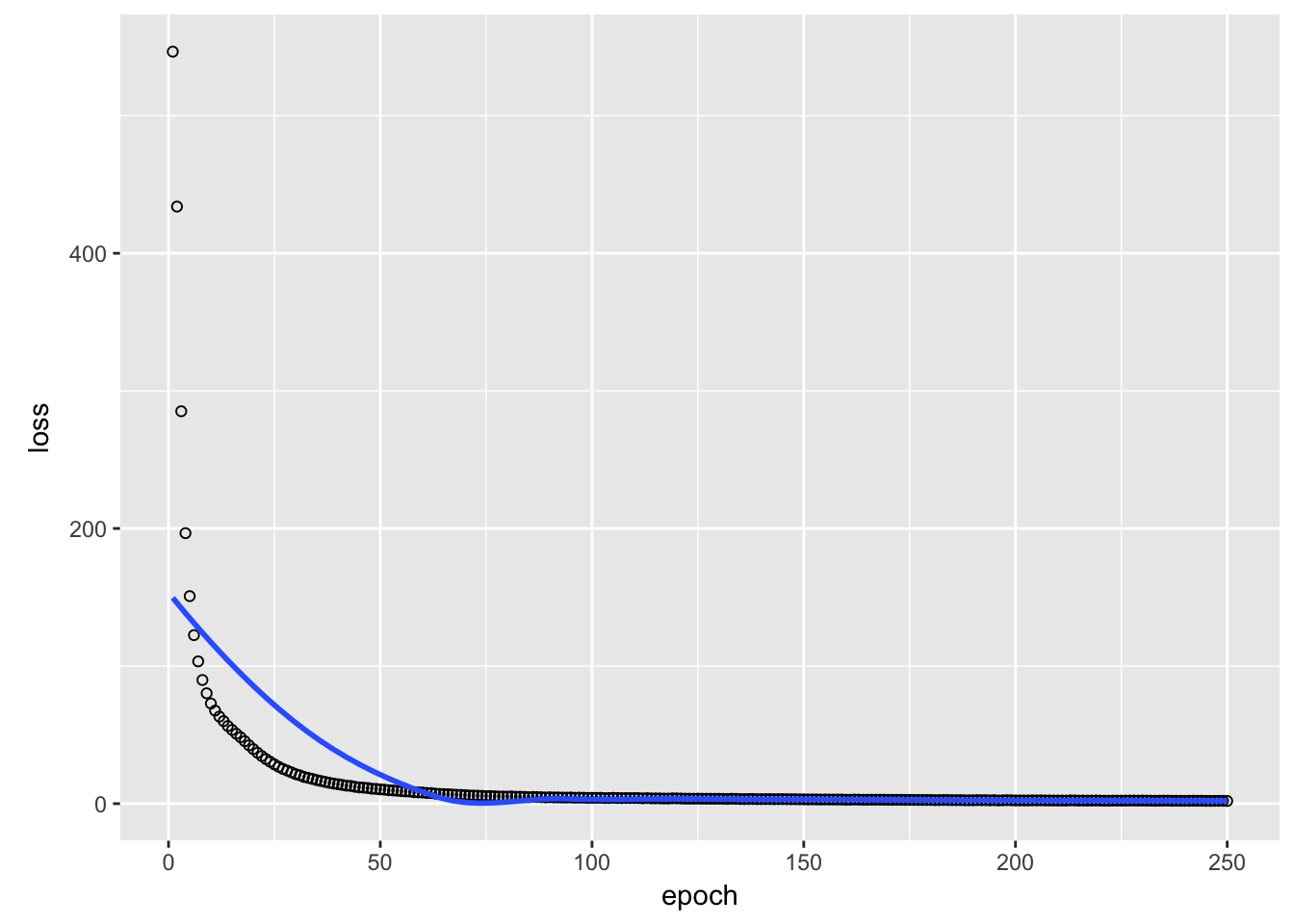
# 損失関数のグラフ
plot(historyTrain)
pred = predict(model, x_test)
result_mse = data.frame(correct_value = y_test, MSE = pred)
損失関数のカスタマイズ
パッケージで提供されている以外の損失関数を定義するには、kerasのバックエンド(tensorflow)で定義する必要があります。(https://keras.rstudio.com/articles/backend.html)
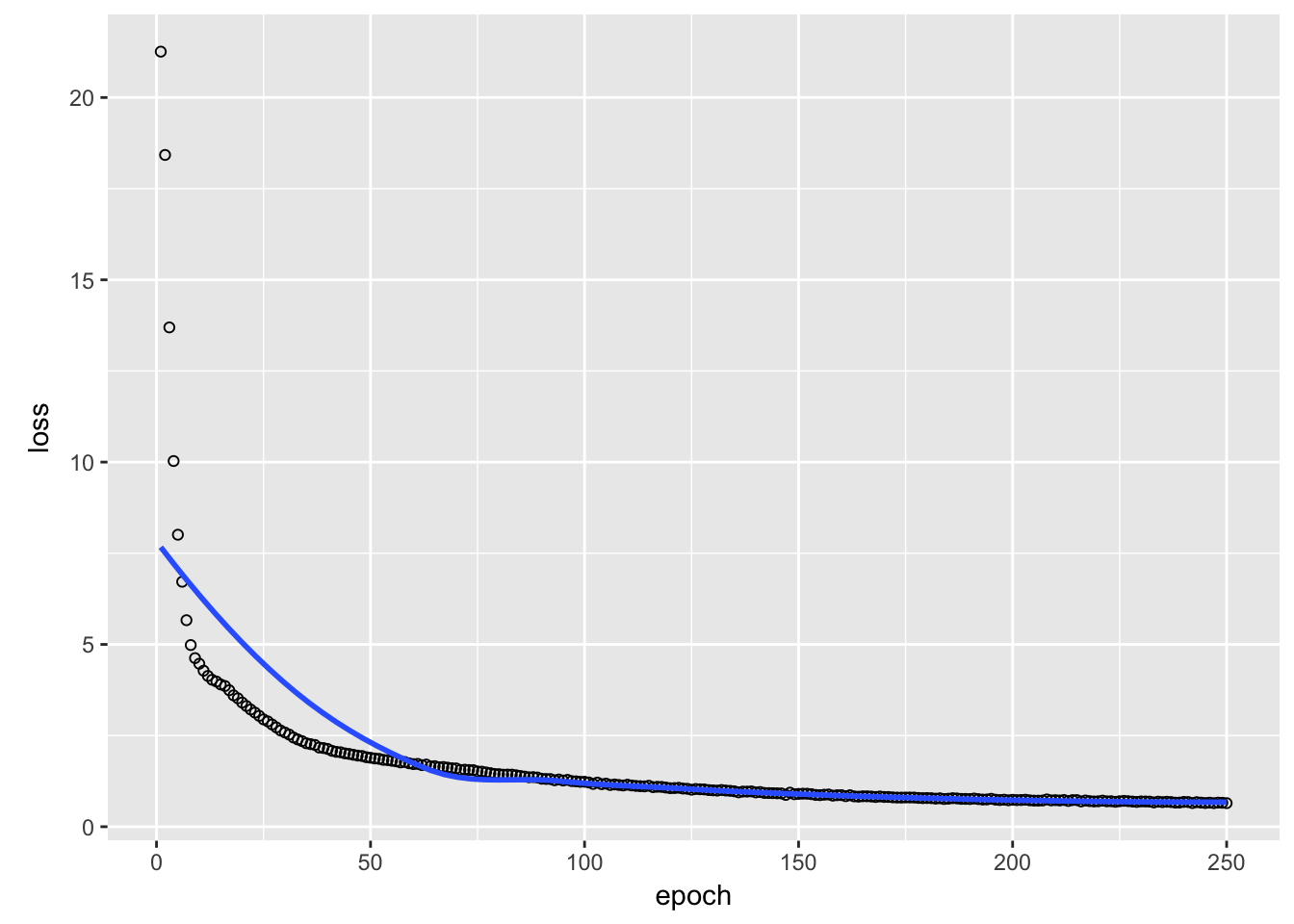
またHuber関数、その他の損失関数の定義はこちらを参照。(https://bi.biopapyrus.jp/ai/machine-learning/loss-function.html) Huber関数は外れ値による過学習を抑えることができるのが特徴です。
huberloss <- function(y_true, y_pred){ a = k_abs(y_true – y_pred) loss = k_switch(k_less_equal(a, 1.0), 0.5 * k_square(a), a – 0.5) return (k_mean(loss)) } # Huber Lossで同じモデルを立ち上げる model = keras_model_sequential() model %>%
layer_dense(units = c(ncol(x_train)), activation = “tanh”, input_shape = c(ncol(x_train)), name = “firstLayer”) %>%
layer_dense(units = ncol(x_train), activation = “tanh”, name = “secondLayer”) %>%
layer_dense(units = 1, activation = “linear”, name = “predictions”)
model %>% compile(optimizer = optimizer_nadam(), loss = huberloss)
# トレーニングの実行
historyTrain = model %>% fit(x_train, y_train, epochs = 250, batch_size = 5, verbose = 0)
plot(historyTrain)
# 価格予測
pred = predict(model, x_test)
result_hl = data.frame(correct_value = y_test, HuberLoss = pred)
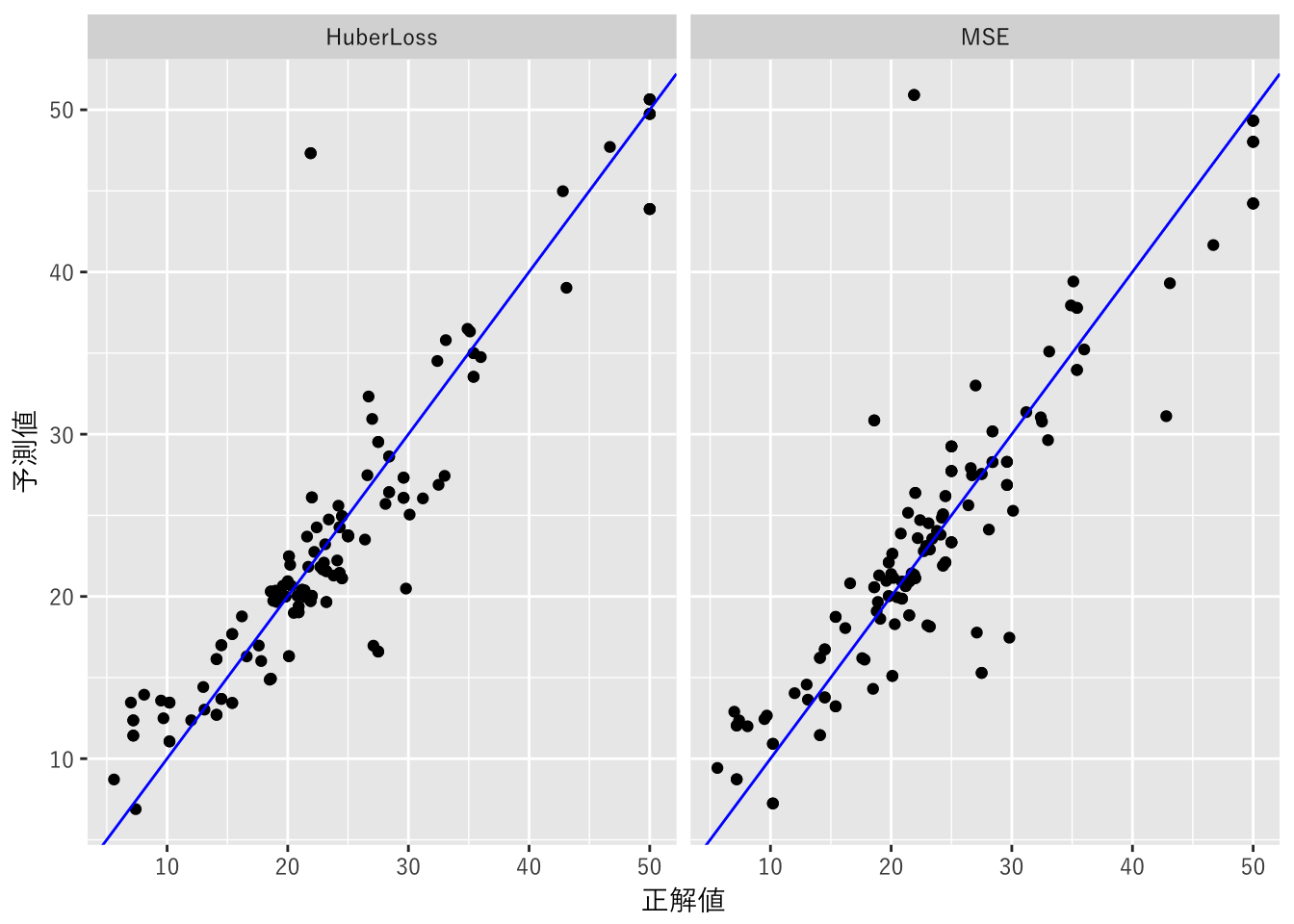
予測値
最後にMSE, Huber Lossを使った予測値を以下のグラフで対比してみました。MSEは外れ値の影響でHuber Lossに比べ同じ条件下ではエラーが大きく出ています。
簡単ですが、Kerasの使い方をメインにニューラルネットの使用例を紹介しました。みなさまも是非試してみてください。
final_results = left_join(result_mse, result_hl, by = ‘correct_value’)
final_results = gather(final_results, “model”, “prediction”, 2:3)
final_results$error = (final_results$prediction – final_results$correct_value) ** 2
colnames(final_results) = c(‘正解値’, ‘モデル’, ‘予測値’, ‘エラー’)
ggplot(data = final_results, aes(x = 正解値, y = 予測値)) + facet_grid(.~モデル) + geom_point() + geom_abline(slope = 1, intercept = 0, color = ‘blue’) + theme(text = element_text(family = fontJP))
errors = final_results %>% group_by(モデル) %>% summarize(二乗誤差 = sum(エラー))
knitr :: kable(errors, caption = “モデル比較”)

AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。

 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス