
なぜ日本企業は「ビッグデータ集めなきゃいけない病」にかかるのか?

私は、シリコンバレーに拠点をもつAIビジネスデザインカンパニー、パロアルトインサイトのCEOとして、過去50社以上の日本企業にAI技術活用に関するアドバイスや導入をしてきました。
業界特化型のAIソリューションを提供する会社ではなく、業界横断的に企業のニーズを見て、それに対してAI技術を駆使した解決策を提案、実装してきた中で見えてきたことがあります。
それは、多くの日本企業、それも超一流の会社ばかりが、「データ集めなきゃいけない病」にかかっているということです。

弊社のクライアント企業の経営陣は、よく以下のような質問を投げかけて来ます。
•集められるデータを集められるだけ収集しないと、AI活用できないのか?
•分析するのは「ビッグデータ」じゃないといけないのか?
•どれだけの容量のデータが集まれば、「解析するのに十分だ」と言えるのか?
データが十分に集まっているだけでは、ゴールにたどり着けません。それを考えるきっかけとなる例が、少し前にみつけたこの記事にありました。
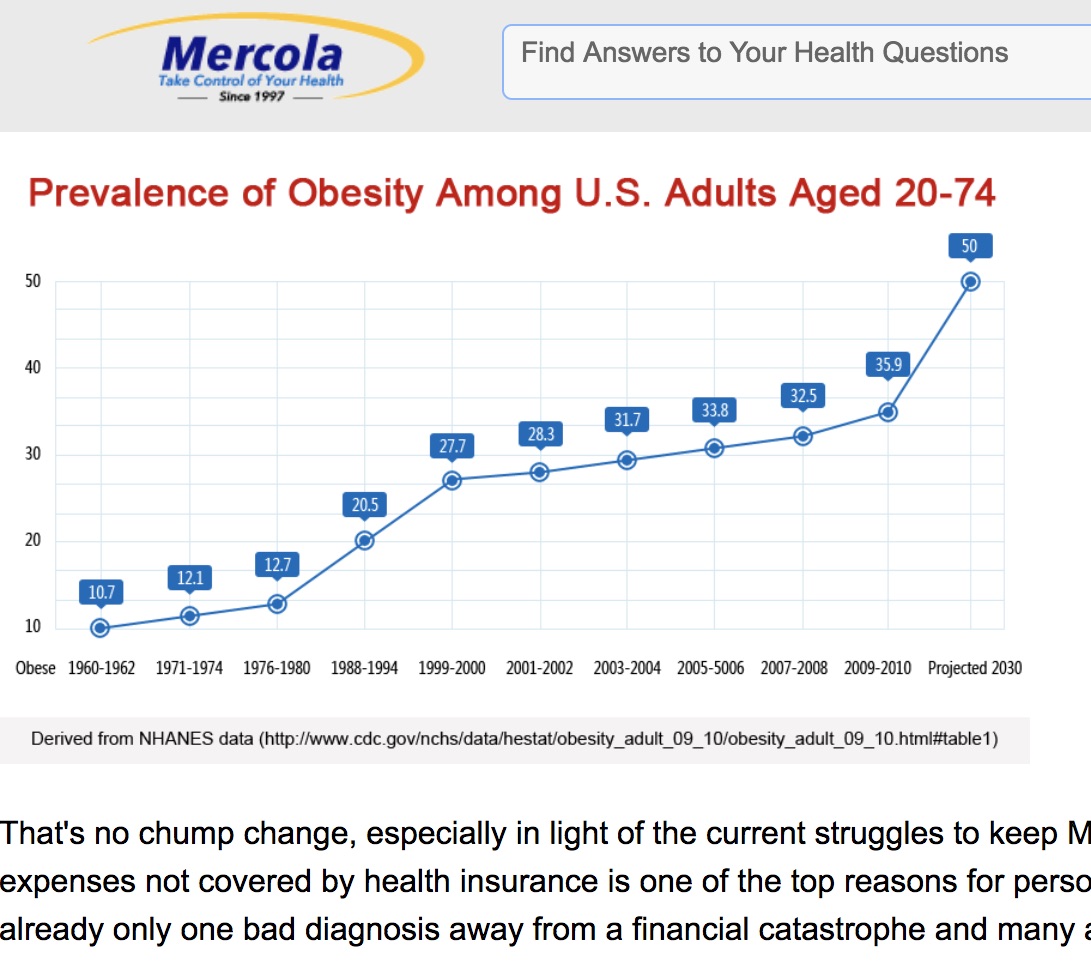
IoTで取得できるようになった健康データの量と、アメリカ人の肥満率レベルをまとめたものです。
関連記事:Does More Data Really Lead To Better Decision Making?(Forbes)
記事が投げかける疑問は端的でユニークです。
IoTデバイスやウェラブルが溢れたことで、消費者は毎朝、コネクテッド体重計から体重や体脂肪率を記録できるようになり、ウェラブルデバイスで心拍数や血中酸素濃度を数秒ごとにモニタリングし、消費カロリーも計算できるようになりました。それなのに、何故アメリカでは肥満率が減少しないのか? しかも「23andMe」のような遺伝子解析サービスを使えば、自分の遺伝的な属性データまで見えるようになったのに、です。
アメリカ人口の肥満率は現在約37%。2030年には50%(2人に1人が肥満)になると予測されています。データが集まったからといってゴールではなく、 データを解析して示唆に落とし込む能力がなければ、そしてその示唆を使って問題解決までやりぬく意思、そこまでのメカニズム作りをするコミットメントがなければ、結果につながらないことを表しています。

同じことが企業のAI活用プロジェクトにも言えます。例えば、弊社に相談に来るクライアント企業の中には、「まだこれくらいしかデータが溜まっておらず、見てもらうには不十分ではないかと思っている」というような懸念を抱いている企業もあります。でも、その後実際に手元にあるデータを見てみると、既に面白い解析ができることがわかりました(そういうケースは少なくありません)。
ここで大事なのは、データ集めは非常に大事なステップですが、最初の0.8歩に過ぎないということです。データ解析やAI技術導入の準備に時間をかけすぎていて、「やっとビッグデータが溜まった」と思ったときにデータサイエンティストに大量のデータを丸投げする、というプロセスは非効率的なのです。
それよりも、最初の段階からデータサイエンティストを交えて、ゴールを志向しながら逆算的アプローチでデータを収集、解析した方が良い結果が確実に出ます。
以前、 ビッグデータを保有している企業のデータを拝見したのですが、その7割ほどがゴール(データを使って新しい収益モデルを生み出したい)到達のためには使えないデータでした。そして残りの3割の有益なデータも、ラベル付けがされていない等の理由からすぐには解析して示唆にできる状態ではありませんでした。
こうなる前に、まず、どんなデータを集めるべきか、どんなラベル付けをすべきか、というところをデータサイエンティストと話しながらデータ収集をした方がよほど効率的なのです。

「ビッグデータでなければいけないのか」
この質問も度々企業から投げかけられますが、答えはNOです。
そもそもビッグデータを持ち合わせている会社は多くありません。むしろスモールデータから何が見えるかという分析手法の方が、ノイズが少なくて早く結果が出ると言う声もあります。
データ容量が多いことにこしたことがないケースも多くありますが、全てにおいてそうではないのです。画像認識などで使われるディープラーニング(深層学習)のようなビッグデータが必要と思われている技術でも、同じことが言えます。Google Brain TeamのAI研究者であり オープンソースのニューラルネットワークlibraryの「Keras」を開発したFrançois Chollet氏も自身の著書『Deep Learning with Python』で、シンプルなモデルでタスクが簡単な場合は、数百行のデータでも十分な場合も多くある、と言っています。
また、Deep Learningのモデルは再利用可能かつ無料で公開されているものが多く、ImageNetなどのデータセットを元にトーレニングされた*ニューラルネットワークから学習を開始することができるので、その場合は自分でゼロからビッグデータを集める必要がない、と語っています(出典:「Deep Learning with Python by François Chollet」のP.130より) 。
AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。


 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス