(この記事はEdouard Harris氏が書いたThe cold start problem: how to build your machine learning portfolioを、著者の許可を得て日本語訳したものです。)
私はY Combinator出資のスタートアップ企業に勤務する物理学者です。我々は新卒の学生が機械学習の仕事に付くことを支援しています。一昔前に、機械学習の仕事に付くためにすべきことについて書きました。その投稿の中でやるべきことの一つとして、機械学習プロジェクトのポートフォリオを作ることをお勧めました。しかし、どのようにすればポートフォリオを作れるかということについては書かなかったので、今回の投稿ではその話をします。[1]
我々のスタートアップの事業がら、私は良いものも悪いものも含め数百に登るプロジェクトを見て来ました。その中から2つの素晴らしいプロジェクトを紹介します。
この話は実話です。プライバシーを守るために名前は変更しています。
X社はAIを使ってスーパーマーケットが新たな在庫を注文するタイミングを知らせるサービスを展開しています。我々の生徒の一人であるロンは、なんとしてでもX社で働きたかったのです。そのために、100%の確率でX社で面接が取れるようなプロジェクトを考案しました。
通常はこのような形で1社をターゲットしたプロジェクトは推薦しません。特に学び始めの段階では、かなりのリスクを伴う戦略です。しかし、ロンはなんとしてもその会社で働きたかったのです。
彼は何を開発したか?

赤い四角が足りない商品を示す
X社はものすごく有能で、業界の中でも有数の技術を保有しています。それでも、ロンのプロジェクトは4日も立たないうちにX社のCEOの目に止まりました。
もう一つの実話です。
アレックスは大学で歴史を先行しながらロシア言語学を勉強していました(本当の話です)。歴史専攻にしては珍しく、機械学習に興味を持ちました。さらに珍しく、彼は1行のPythonを書いたこともないのに、機械学習を学ぶことを決意しました。
アレックスはハンズオンで学ぶことにしました。彼は飛行機の中で意識を失ってしまったパイロットを検知するための分類機を作ることにしました。アレックスはパイロットの動画から検知することを目標としました。人間が動画を見れば比較的簡単にパイロットが意識を失っていることを検知できることを知っていたので、機械にも検知は可能だろうと当たりを付けていました。
アレックスはそれから数ヶ月かけて次のようにプロジェクトを進めていきました。
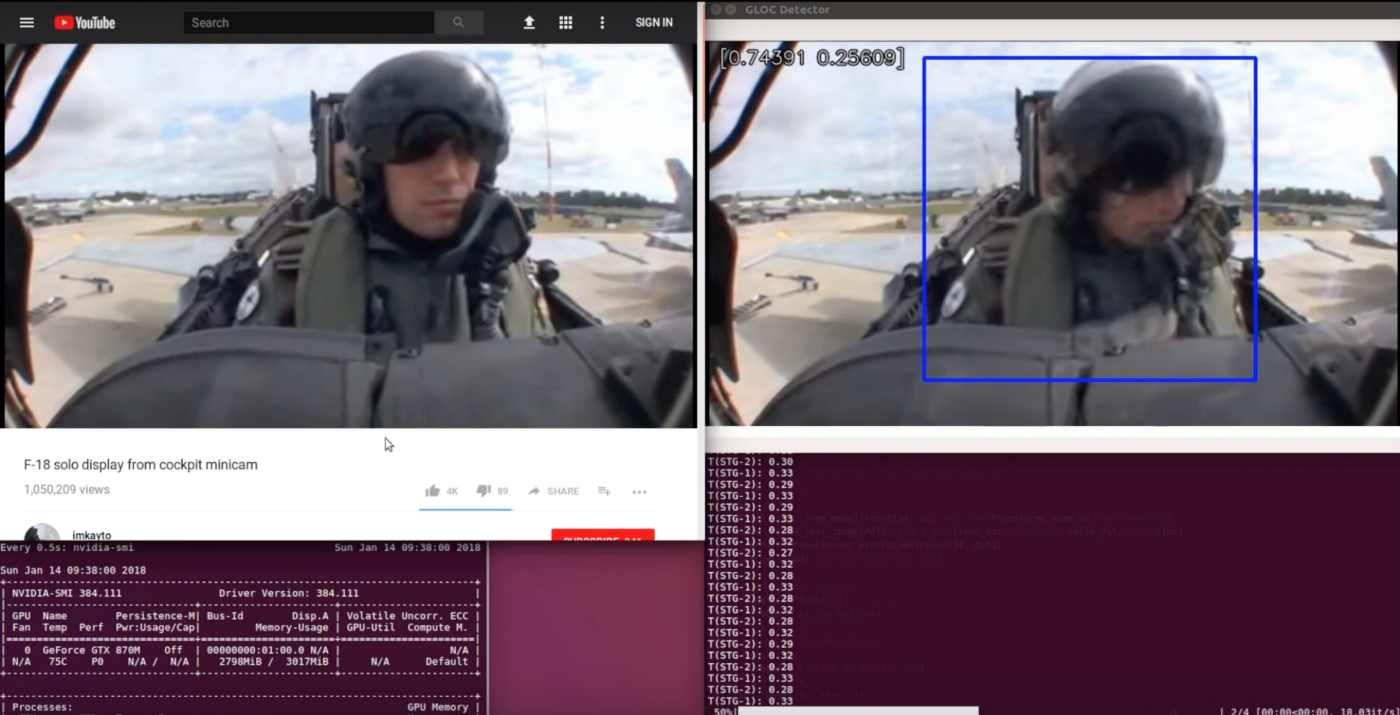
アレックスの無意識検知分類機のデモ
もちろんアレックスはモデルの精度を改善するつもりでしたが、その機会がないうちに採用されてしまったのです。モデルの精度なんかよりも、彼のデータを集める姿勢や、プロジェクトのビジュアルなインパクトの方が企業にとって魅力的だったのです。
アレックスが歴史先行でロシア言語学を勉強していたことは言いましたっけ?
彼らの成功要因はなんだったのか?彼らは以下の4つのことをものすごくうまく実行しています。
このようなプロジェクトは1回か2回やれば十分です。アレックスとロンのプロジェクトは何回も他の面接で再利用されました。
なので良い機械学習プロジェクトの秘密を要約するならば、「集めるのに苦労した面白いデータセットを使ってビジュアル的にも興味を惹くプロジェクトを作る」ということになります。
あなたがプロジェクトのアイデアがありそのアイデアの評価が必要な場合はツイッターで聞いてください。私のハンドルは@neutronsNeuronsで、DM歓迎です:)
[1]なぜこれが重要かというと、採用担当者はあなたの過去の経歴を見ながら判断するからです。もし全くの未経験者ならば個人プロジェクトがそれの代替となります。
[2]ロンのプロジェクトは完璧とは程遠いものでした:X社はかなりの資源を投入してこの問題に取り組んでいました。しかし、あまりにも似ていたため、X社からレポジトリーをプライベートに変更してくれと頼まれました。
AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。

 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス