こんにちは。パロアルトインサイト、データサイエンティストの辻です。今回はGoogleによって開発された最先端自然言語モデルBERTの概要についてお話をします。
自然言語処理とは人間が日常的に使っている様々な言語をコンピューターで処理する技術を指し、自動翻訳、音声認識、検索機能や、チャットボットなど様々な場面で実用化が進んでいます。
BERTとはGoogleが開発した自然言語処理のディープラーニングモデル1で、革新的な学習成果を達成したことで有名です。研究で使われている公開データの学習精度でも素晴らしい成果を出しましたが、ビジネスへの適応性が非常に高く、Googleサーチに新しく導入され10%の検索結果でその効果が検証されました。[Understanding searches better than ever before by google]
ではBERTモデルは他の自然言語処理モデルとどのような点が大きく違うのでしょうか?
まず大きな違いはこれまでの自然言語モデルでは文章分類、翻訳、感情分析など特定の学習タスクに対して1つのモデルを用いていたのですが、BERTモデルは転移学習2をすることが可能になり、1つのモデルをチューニングすることで、様々な問題に対応することができるようになりました。(汎用性の獲得)
図表1:BERT モデル事前学習とファインチューニング [1]
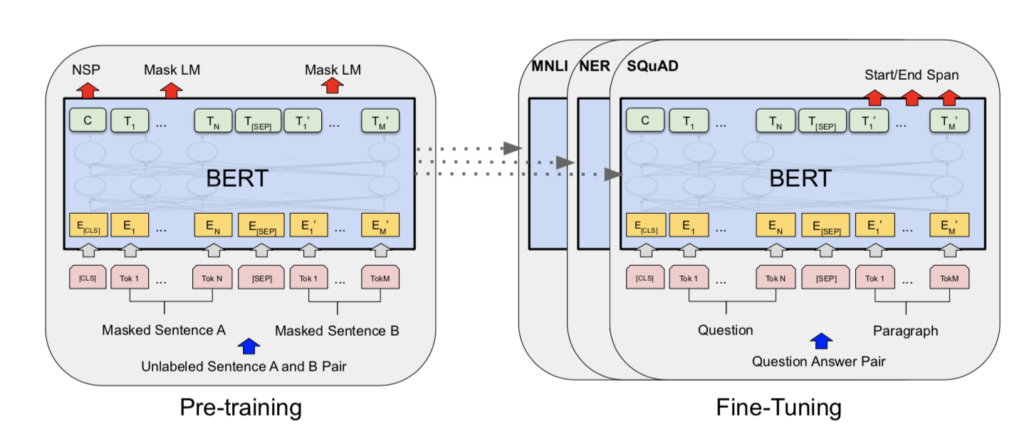
次に以前はモデルごとに語彙を1から学習させるため、非常に多くの時間とコストがかかっていました。BERTではオープンソースで公開されている文脈を既に学習させたPre-Training BERTモデルを使用して、これまでより少ないデータセットで短時間で学習ができるようになりました。少ないデータセットでさまざまな学習ができる理由は、データ上のラベルを使わない教師なしデータで事前学習を行ったモデルが公開されているからです。これを外国語を学んでいる人間に置き換えるとすれば、すでに大量の単語と文法を覚えていて、あとは文章を読んで読解力を身につけるだけの状態になっているようなものです。(学習プロセスの効率化)
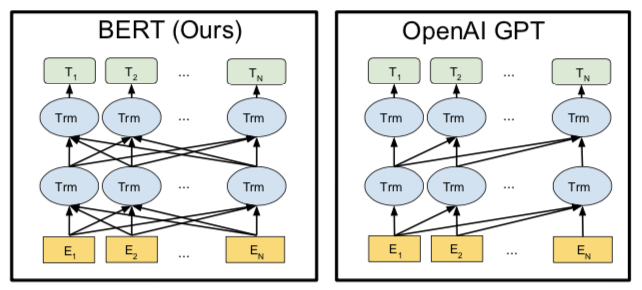
実はこのような事前学習をするモデルはOpen AIが開発したGPT(Generative Pre-trained Transformer)モデルなどでも開発されていますが、BERTでは語彙を前から後ろ、後ろから前の双方向から文脈の学習を行いさらに高い精度で文脈を解析します。下図ではOpanAI GPTが左から右に対して矢印が繋がっているのに対し、BERTでは前後全てのノードにニューラルネットワークが連結されているのがわかります。
BERTとOpenAI GPTのネットワークの違い [1]
BERTモデルは今まで開発された様々な自然言語処理のモデルの良いとこどりをし、ビジネスアプリケーションにも適応できる非常に有能なモデルであることがわかります。今回は概要についてのお話でしたが、次回は実際にサンプルデータを使い、Fine-Tuningの仕方についてコードサンプルも交えて書きたいと思います。
引用:
[1] Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (11 October 2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. arXiv:1810.04805v2
1 ディープラーニング:機械学習モデルのニューラルネットワークを多層に組み合わせて使用した学習モデル
2 転移学習:シミュレーターなどの類似した問題で仮データで学習したモデルを使い、少ない実データでよりよく学習する学習方法
実際の導入に関しては、AI導入/DX推進プロジェクトを成功させる3つアドバイスもぜひご参考ください。
BERT の学習時間を削減する研究論文「Early BERT」について、The Insight の記事「BERT(自然言語処理)の学習時間を削減する「モデル圧縮」とは」としても取り上げました。こちらもぜひご確認ください。
AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。

 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス