画像からの「教師あり学習」と動画からの「教師なし学習」を組み合わせるアプローチ
パロアルトインサイトの石角です。「The Insight」で何度も紹介してきた画像生成AIは、直近の数ヶ月間で一般の人が利用できるものが次々に登場し、SNSを通じて大きな話題となりました。
次に大きなトレンドとなると予想されるのが、動画生成AIです。2022年9月、Metaが「Make-A-Video」と名付けた新たな動画生成AIを発表し、注目を集めています。

シリコンバレーから現役データサイエンティストのインサイトをお届けする「The Insight」。今回取り上げるのは、Metaが開発した動画生成AI「Make-A-Video」です。
論文データ:今回のディスカッション対象の論文をご紹介します。
タイトル:Make-A-Video: Text-to-Video Generation without Text-Video Data
著者:Uriel Singer et al.
掲載サイト:arXiv
発行日:2022年9月29日
引用数:
URL:https://arxiv.org/abs/2209.14792
Make-A-Videoは、2022年9月にMetaが発表した「動画を生成するAI」です。Make-A-Videoは以下の3種類の入力情報から、動画を生成できます。
Make-A-Videoの最も主要な手法な用途は、「文章から動画を生成すること」です。短い指示文を与えるだけで、Make-A-Videoは文章の意味に合った動画を生み出します。
Make-A-Videoが生成した動画は公式サイトで公開されているので、見てみるとよいでしょう。公式サイトから2つ例を引用すると、以下の通りです。どちらの例でも、文章で指示された通りの動画が生成されていることが確認できます。

(画像引用:https://makeavideo.studio)
A dog wearing a Superhero outfit with red cape flying through the sky (日本語訳:赤いマントのスーパーヒーローの服を着て空を飛んでいる犬)
Make-A-Videoは、入力情報として「文章」ではなく「画像」も扱えます。画像が1枚与えられると、Make-A-Videoはその前後の時間軸の画像を生み出し、画像をつなげて動画を生成します。
下図の例では、Make-A-Videoは左側の絵画の画像を入力として、右側の動画を生成しました。嵐の中を進む小舟の様子を、まるで現実の映像のように描写しています。
また、Make-A-Videoは2枚の画像を入力として、画像間の時間を補完する動画を生成することも可能です。その例が下図で、無重力の宇宙空間にある岩が動いていく様子を表現しています。
Make-A-Videoは「動画」を入力として、別の「動画」を生み出せます。オリジナルの動画の特徴を反映させつつ、少し異なるバージョンの動画を生成するのです。
その例が下図です。Make-A-Videoが生み出した動画は、「宇宙空間に浮かぶ宇宙飛行士」という点ではオリジナルと同じですが、まったく別の動画となっています。
Make-A-Videoの技術的な側面を解説します。
進歩が著しい画像生成AIと比べると、動画生成AIはまだまだ発展途上です。公開されているMake-A-Videoが生成した動画の中には、現実ではありえない動きをするものも混じっています。
動画生成AIの開発が遅れている理由としては、まず動画は画像よりも情報量が多く複雑だという点があります。それに加えて大きな要因となっているのが、「文章と動画の組み合わせ」のデータセットが少ないことです。
画像生成AIは、インターネット上から「文章と画像の組み合わせ」を大量に収集して学習することで、性能を高めました。しかし、動画では十分な「質」と「量」のデータセットを集められないため、画像と同じアプローチが有効ではないのです。
AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。


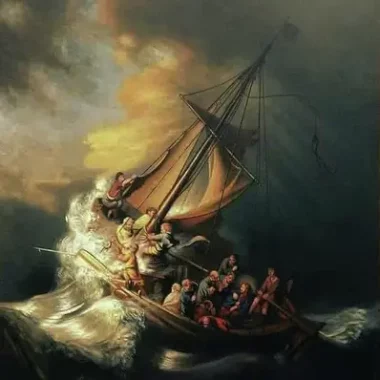






 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス