
こんにちは、CTOの長谷川です。
「機械学習のモデルを作るためにどれだけのデータが必要ですか」という質問をよくクライアントの経営者の方から聞かれます。ディープラーニングで学習する場合、大体1クラスに付き5,000件程度のデータがあればまずまずのパフォーマンスが発揮されますが、人間レベルの精度を求めるとすると約10,000,000件という大規模なラベル付きデータが必要になります(Goodfellow et al. 2016)。5,000件と10,000,000件の間には大きな隔たりがあります。10,000,000件となるとこれはもう大規模な予算を抱えている大企業か、既にデータ収集の仕組みの中で容易にそのような規模の良質なラベル付きデータがあるケースしかその分量を準備することができません。5000件ですらラベル付きデータを準備するのに苦労するケースが多々あります。例えばパロアルトインサイトが実施するプロジェクトの現場においては、データの機密性が高いことが多いため、アマゾンのメカニカルタークやパートの人材を雇ってラベル付けをさせるということができないケースがあります。
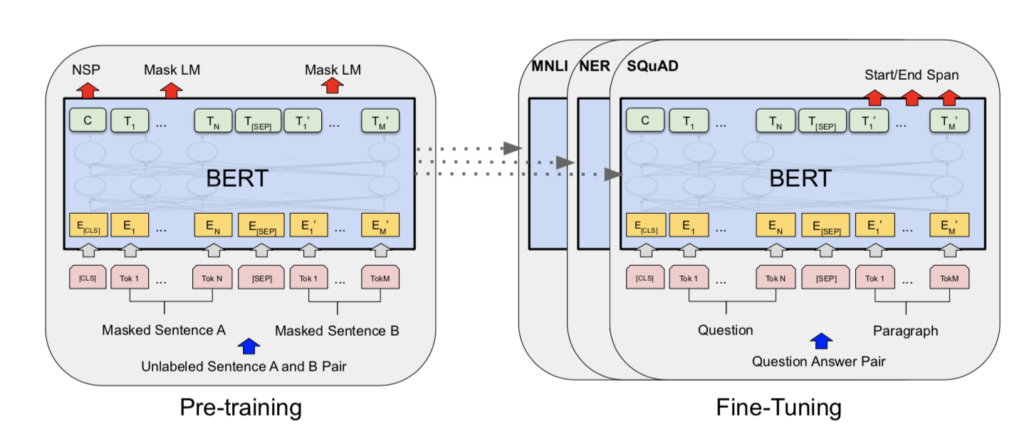
この課題を乗り越えるために、2種類の解決策をパロアルトインサイトでは多用しています。一つはPretrained model、すなわち別のデータで既に学習ができているモデルを活用し、自分たちの用途にチューニングしていくという方法です。これについては、例えばグーグルのBERTモデルなどを活用します。BERTについては、パロアルトインサイトのデータサイエンティスト辻がブログ記事を書いているのでそれをご参照ください。
AIの活用提案から、ビジネスモデルの構築、AI開発と導入まで一貫した支援を日本企業へ提供する、石角友愛氏(CEO)が2017年に創業したシリコンバレー発のAI企業。
社名 :パロアルトインサイトLLC
設立 :2017年
所在 :米国カリフォルニア州 (シリコンバレー)
メンバー数:17名(2021年9月現在)
パロアルトインサイトHP:www.paloaltoinsight.com
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com

2010年にハーバードビジネススクールでMBAを取得したのち、シリコンバレーのグーグル本社で多数のAI関連プロジェクトをシニアストラテジストとしてリード。その後HRテック・流通系AIベンチャーを経てパロアルトインサイトをシリコンバレーで起業。東急ホテルズ&リゾーツのDXアドバイザーとして中長期DX戦略への助言を行うなど、多くの日本企業に対して最新のDX戦略提案からAI開発まで一貫したAI・DX支援を提供する。2024年より一般社団法人人工知能学会理事及び東京都AI戦略会議 専門家委員メンバーに就任。
AI人材育成のためのコンテンツ開発なども手掛け、順天堂大学大学院医学研究科データサイエンス学科客員教授(AI企業戦略)及び東京大学工学部アドバイザリー・ボードをはじめとして、京都府アート&テクノロジー・ヴィレッジ事業クリエイターを務めるなど幅広く活動している。
毎日新聞、日経xTREND、ITmediaなど大手メディアでの連載を持ち、 DXの重要性を伝える毎週配信ポッドキャスト「Level 5」のMCや、NHKラジオ第1「マイあさ!」内「マイ!Biz」コーナーにレギュラー出演中。「報道ステーション」「NHKクローズアップ現代+」などTV出演も多数。
著書に『AI時代を生き抜くということ ChatGPTとリスキリング』(日経BP)『いまこそ知りたいDX戦略』『いまこそ知りたいAIビジネス』(ディスカヴァー・トゥエンティワン)、『経験ゼロから始めるAI時代の新キャリアデザイン』(KADOKAWA)、『才能の見つけ方 天才の育て方』(文藝春秋)など多数。
実践型教育AIプログラム「AIと私」:https://www.aitowatashi.com/
お問い合わせ、ご質問などはこちらまで:info@paloaltoinsight.com
 |
 |
※石角友愛の著書一覧
毎週水曜日、アメリカの最新AI情報が満載の
ニュースレターを無料でお届け!
その他講演情報やAI導入事例紹介、
ニュースレター登録者対象の
無料オンラインセミナーのご案内などを送ります。






 いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する
いまこそ知りたいDX戦略 自社のコアを再定義し、デジタル化する  “経験ゼロ”から始める AI時代の新キャリアデザイン
“経験ゼロ”から始める AI時代の新キャリアデザイン  いまこそ知りたいAIビジネス
いまこそ知りたいAIビジネス